A layman’s guide to data platforms
Introduction
In my last post I have outlined a few options to accelerate game development using data analytics and listed some resources to get started. I hope after some fiddling around you realized that manually combining data sources and prefabricated reports isn’t cutting it and many tools are limited to a specific use case such as marketing or system monitoring.
Well, how can we enable our team to work daily with data and explore more options? I almost always hear someone saying: “We have a database, let's build some SQL queries, export the outcome to Excel and everything is going to be awesome!“ While technically this is true, I strongly advise against using the operational databases or rely only on Excel (or any spreadsheet software for that matter) to do data analytics.
Why? Great question. A few reasons in no particular order:
It’s your operational database, therefore performance degradation directly impacts your players and systems.
Your operational database is optimized for CRUD and the requirements for analytical tools or queries are vastly different.
In some cases you delete records and they are not available for analytics and reports anymore.
Your database is built for machines not humans. Tables and columns as well as the data itself is extremely normalized and difficult to work with.
You should never (little to no exceptions) let a human execute queries on your production database.
Spreadsheet software is not a database and can usually only hold up to ~1 Million rows. Trust me, this limit is very easy to reach in the current day and age.
In my opinion, spreadsheets are often rather difficult to read and it is cumbersome to interpret spreadsheet formulas. Additionally, they are hard to govern and version control.
While spreadsheets are great working options on a very detailed level, it lacks features working with high level data across multiple sources.
There are several more reasons but do we have a better option? Also great question! Let me introduce you to the data platform.
A data platform is a collection of concepts, techniques and tools specifically designed for big analytics, business intelligence as well as scientific processing. It often feeds processed data back to operational systems. An example would be user churn predictions, fraud detection, segmentation, etc…
In my opinion these are the core concepts every data platform consists of:
Data Extraction
Data Lake
Data Warehouse
Data Modelling
Data Analytics & Visualisation
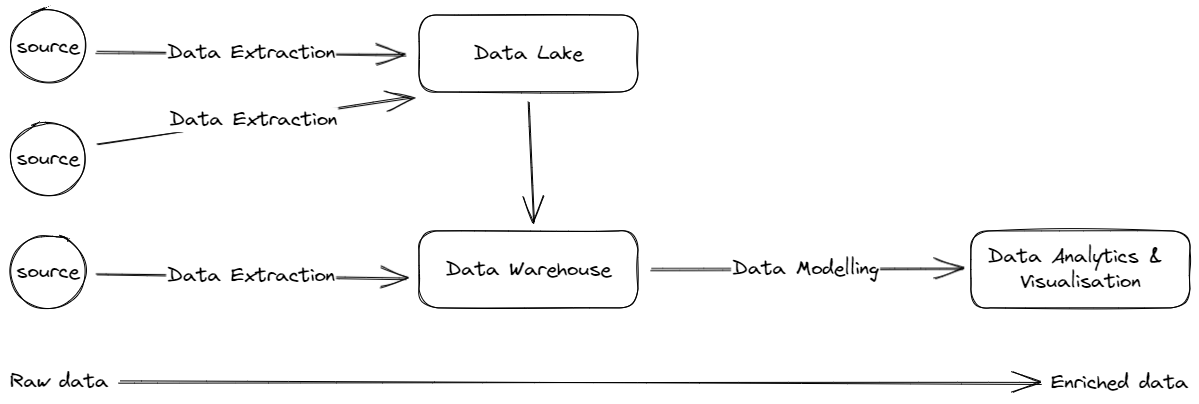
Example overview of the core concepts in a data platform
Data Extraction
In order to work with data we need to extract it from different sources, like an internal database, an external data source like SFTP, a REST API, an email attachment or a file laying on your desktop. In many cases data is being ingested into a data lake and sometimes it is directly loaded into the data warehouse for further processing. The following methods are commonly used approaches to extract data:
Full extraction: Get all records.
Delta extraction: Get all records that have been produced since the last extraction.
Change data capture: Trace all the changes (CRUD) made to a database record.
Message streams: Messages are created by producers/publishers and passed to multiple consumers/subscribers as soon as possible as well as in order.
As with most technical problems, the best decision always depends on the needs. While streaming data might be the holy grail of data architecture, I must stress how difficult it is to pull it off. In addition, you should always ask the question: What can be done with the benefit of real time data extraction in contrast to daily, hourly or 15-minute batches? For a starter setup I would recommend using a tool like Fivetran, Meltano or Airbyte - either managed or self-hosted -as they make it very easy to integrate many different sources with simple web interfaces. If you are dealing with highly exotic data sources, I recommend additionally contracting a data engineer to write custom scripts for extracting the data into a data lake of your choice.
Data Lake
The main objective of a data lake is to store all the raw data we might need in the future. Over time, this will lead to massive amounts of data in various formats, such as unstructured binary files like videos or images, semi-structured files like JSON, structured files like CSV, TSV or Parquet. Thankfully, most if not all cloud providers have options to store raw data very cheaply and with almost no limits in so-called object storage services. Most commonly used are Amazon Simple Storage Service (S3), Google Cloud Storage (GCS) and Azure Blob Storage. If you or your company does not plan to leverage a cloud provider, you can use the great open source tool MinIO with an S3-compatible API.
But be careful: A data lake can become a data swamp very fast!
Data Warehouse
This is without a doubt the very core of any data platform. Its main job is to combine as well as structure multiple sources and provide a source of truth for the analytical workload. At first sight, a data warehouse is not much different to a operational database as both have schemas, tables, columns and accept SQL queries but on the backend they are vastly different:
Data warehouses store data in columns rather than in rows.
The query engines are optimized for reading massive volumes of data via complex queries and applying functions like SUM(), AVG(), MIN() & MAX()
Data warehouses are not optimized for simple updates on individual rows.
This is just the tip of the iceberg and there are many more differences but I do not want to get caught up in technical details. Since the big data push in the 2010s, a lot of software has been developed and battle tested. Here are a few options I’ve encountered or used recently:
Clickhouse: An open source data warehouse.
Hydra: A open source Postgres extension enabling column store and a query optimizer.
Google BigQuery: Serverless multi-region data warehouse on GCP.
Amazon Redshift: Serverless multi-region data warehouse on AWS.
Snowflake: Serverless multi-region data warehouse.
Databricks: Technically not a data warehouse: Combines data lakes with data warehouses into a “data lakehouse” for more flexible setups.
Dremio: Open source data lakehouse.
Data Modelling
In order to unify data sources into a single trusted data source and enable users to work with the data, we need to transform it into a data model. This includes the denormalisation as well as structuring of the data so that users can work more easily in the data warehouse and to optimize load processes. A few common methods are Data Vault 2.0, STAR or One Big Table. Each method has some advantages and disadvantages but a common approach is to use Data Vault 2.0 as a core model and add a persistent STAR model on top as a self service layer for data analysts and/or data scientists.
Today's data models need to be agile because the business processes are changing at a rapid pace and more and more sources are connected into the data warehouse. I can recommend using a framework tool like Data Build Tool (DBT) in order to model, deploy and version control the data model. It has killer features, like data documentation, data lineage, environments, macros, plugins, tests and much more. DBT is available as an open source software or a managed service and has a great community.
Data Analytics & Visualisation
Lastly, I want to talk about analytics and visualization. While there are many possibilities and the right toolset really depends on the needs, I can make a few recommendations. You might want to explore your options and think about what is really important to your specific use case but these should get you started.
For data visualization in dashboards or reports, I can recommend the following tools: Metabase, Superset, Tableau & Google Looker Studio.
For self service analytics and exploration use SQL / Python. It's so much faster than using a tool and you're not limited to technical requirements!
If you want to explore machine learning and artificial intelligence: Learn and use Python / Mojo, including their respective data science libraries. (Jupyter Notebooks are great when working with data in Python).
Conclusion
Choosing the right tech stack is not always easy because it depends on so many factors such as company policies as well as legal regulations, data volume, scalability, workforce and much more. Nevertheless, below I provided you with my go to stack for small-ish operations:
Data Extraction: Airbyte and custom scripts directly into the data lake if needed.
Data Lake: I usually stick to the object storage of the preferred cloud provider.
Data Warehouse: Snowflake (Hydra also looks promising but I have not tested it).
Data Modelling: No real question at the moment. DBT!
Data Visualisation: Metabase or Google Looker Studio and SQL.
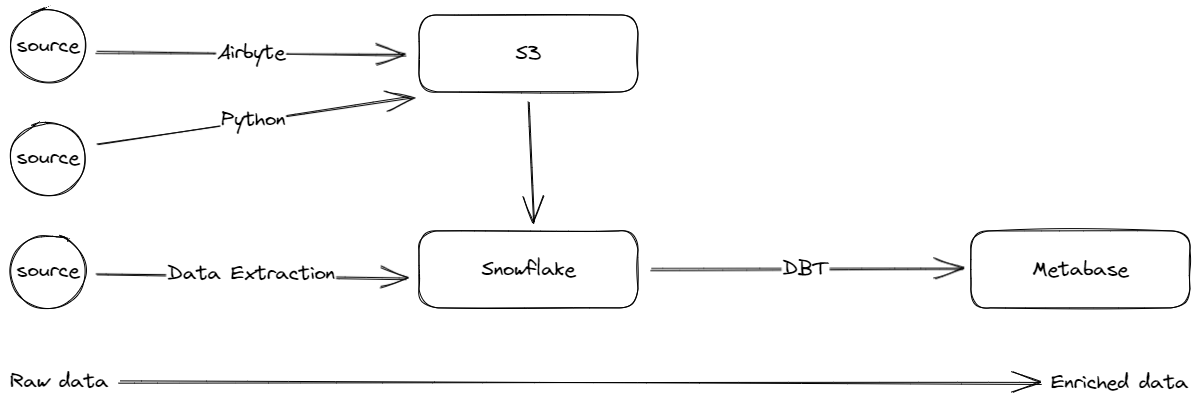
An example Architecture for a small a data platform on Amazone Web Services
While this should get you started with a data platform, it is by far not a complete list and there are many more topics such as:
Data Orchestration & Operation: Deploy development and production environments, manage and schedule data pipelines, trace and investigate issues.
Data Governance: Data tracing, data security, access and retention policies, data documentation and definition of metrics.
Data Pushback: Feed processed data back into operational systems such as emailing services, e-commerce applications, etc...
As you can see, there is so much noise all around, I highly recommend contacting a professional in order to achieve the best possible setup for your needs.
I happen to be a freelance data consultant! So, feel free to shoot me an email :)